
# 第2章:大模型精调平台介绍(基于讯飞星辰Maas平台实现模型精调)

星辰MaaS精调平台 (opens new window):平台以星火认知大模型和优质开源大模型为基础,重点发力数据工程,数据构建质量形成竞争优势,围绕数据管理,模型精调、评估、托管,推理服务完善大模型全生命周期管理,覆盖内容创作、代码、逻辑推理等多场景,无需复杂调整或重新训练,甚至零代码也可以完成精调!
# 1. 前言
在人工智能飞速发展的当下,模型的精准定制成为众多企业与开发者追求高效、个性化解决方案的关键。讯飞星辰 MaaS 精调平台应运而生,它以强大且全面的精调全链路功能,为用户打开了通往专属智能模型的大门,引领着智能定制化的新潮流。本文将结合具体案例,从创建数据-选择模型-精调训练-效果评估的全链路使用流程来介绍精调功能及其亮点。

# 2. 大模型精调使用流程
我们以精调一个【商品评论情感分类模型】为例,来展示精调的全链路使用流程。
# 1.构建数据集
在进行精调训练前需要明确目标任务和数据需求,并准备好相关训练数据,星辰MaaS精调平台提供了丰富的**【预置数据集】可供用户直接用于训练,也可以选择【创建数据集】,平台提供【问答对抽取】、【数据增强】、【prompt工程】**三种辅助工具来优化数据,进一步提高数据质量。
数据集的获取有两种主要途径:
- 依据特定业务需求**自行定义数据集。**这种方式能够确保数据与业务场景紧密贴合,从而提升模型在实际应用中的表现。
- 利用**公开数据集资源。**公开数据集丰富多样且涵盖广泛的领域,能够满足许多常见任务的基础数据需求。
平台为大家提供了预制数据集(数据集管理-预置数据集),可直接用于模型训练;同时配备了问答对抽取功能,我们只需导入文本文件或网站链接,系统便能自动切分问答对,快速生成训练所需的数据。
预置数据集 |
问答对抽取 |
|---|


# 方法1:预置数据集
平台提供的预置数据集包括多个行业领域,可以选择相应领域的数据集进行模型精调,但「预置数据集」本身不支持用户更改转化。
这里我们也可以直接选择平台预置数据集里的“sentiment_predict”开源数据用于训练情感分类

# 方法2:创建数据集
您也可以通过创建数据集来上传自己的训练数据,目前仅支持导入json、jsonl、csv格式的单个文件,具体可参照模型精调数据集格式 (opens new window)说明。
 |  |
|---|
# 数据辅助工具
# (1)问答对抽取
如果您只有文本数据,无问答对数据,您可以使用平台的【问答对抽取】功能,选择导入txt等格式文本文件或网站链接,平台能够自动切分问答对,也支持您自定义切分分隔符,自动抽取问答对数据。
 |  |
|---|
【问答对抽取】得到Q&A对数据集满足大模型精调数据集所需格式,正确率可达90%,覆盖率不低于75%,可以下载生成的数据集用于精调。
 |  |
|---|
# (2)数据增强
如果您原本的数据量过少,平台提供数据增强功能,可以对常见文本生成、理解、知识问答数据泛化,扩展数据集数量。在【数据增强】板块,您可以通过【创建任务】实现批量增强,支持选择增强倍数和质量等方式,也可以通过【在线增强】和【在线优化】来查看单条数据增强的效果。
 |  |
|---|
# (3)prompt工程
如果您不知道如何优化数据集,平台支持基于prompt工程的数据集构建优化,提供50+常见prompt模板,满足多种类型数据需求。
 |  |
|---|
根据训练集数据格式要求调整数据集对应成instruction、input、output里的内容,经过处理,最终形成的一条完整数据格式应该如下所示:
{"instruction": "你是一个情感分析助手,目标是辨别推文的情感倾向,情感倾向分为积极和消极。接下来,我会给你推文的内容,请你告诉我情感分析的答案",
"input": "一百多和三十的也看不出什么区别,包装精美,质量应该不错",
"output": "积极"}
# 数据集划分
在进行SFT时,为了确保模型评估的公正性,通常需要将数据集划分为训练集、验证集和测试集:
训练集:用于训练模型的主要数据集。
验证集:在微调过程中用于调优超参数和选择最优模型。
测试集:用于最终评估模型性能,确保微调后的模型在未见数据上的表现。
常见的划分比例为 70% 训练集、15% 验证集、15% 测试集。
# 2. 模型精调
在进行基础数据的获取和优化后,我们可以选择基础模型、上传训练集进行模型精调训练。平台提供了文本对话模型、文生图大模型、图像分类模型、文本分类模型四种类型(PS:图像理解模型即将上线~),包含十几种星火大模型以及开源大模型可以选择。
我们根据任务的复杂程度和场景需求,评估平台上提供的各种模型的尺寸和特性,选择最匹配的模型来完成任务。首先,需要明确任务类型,例如是文本生成、对话、图像分类、逻辑推理等;其次,选择模型尺寸。
- **轻量级模型:**适合简单的文本生成、对话等任务,如 Spark Mini、Spark Mini Instruct,这些模型资源消耗少,训练速度快,适用于日常的内容创作和对话系统。
- **中等复杂任务:**如知识问答、情感分析等,选择 Spark Lite、Spark Lite Instruct,它们在性能与资源需求之间提供了良好的平衡,适合一般的应用场景。
- **相对复杂任务:**对于要求高度精准和复杂任务(如工业自动化中的指令处理或智能家居控制),选择 Spark Max 等更大尺寸的模型,以满足高计算需求和精确度要求。
这里我们选择“Spark-Lite”模型,填写模型名称等信息、训练参数可以按照默认,也支持用户自由调节,点击提交,当任务状态变为运行成功后,即微调任务完成,支持查看loss曲线过程指标等精调信息,loss曲线越收敛精调效果越好,随时评估模型效果~
1.创建模型 |
2.填写模型信息 |
|---|


3.点击提交 |
4.完成精调 |
5.loss曲线 |
|---|



# 2.1 数据配置
在创建模型页面选择刚刚上传的“商品评论情感分类”训练集,进一步进行数据配置工作,明确各个数据字段之间的对应关系。在平台中,Alpaca格式的训练由以下5个字段组成:
- instruction :将与 input 内容拼接,形成模型的输入指令。最终的模型输入指令格式为 instruction\input。
- output :包含模型的期望输出,是训练过程中模型要生成的回答。
- system :如果勾选相关选项,此列的内容将作为系统提示词提供给模型,以便在任务中引入额外的上下文信息。
- history :包含多个字符串二元组,代表对话历史中的指令与回答,有助于模型理解上下文,提升对话生成的准确性。
根据我们此前构建的商品分类数据集格式,数据映射关系如下:
prompt -> instruction
text -> input
label -> output
 数据配置
数据配置
# 2.2 参数配置
在参数配置板块,可以通过调整参数,控制模型训练效果。在本次微调训练任务中,我们先尝试使用平台默认参数配置。点击“提交”按钮即可发起模型训练。
| 参数名称 | 说明 |
|---|---|
| 学习率 | 学习率是模型训练过程中调整权重的步长大小。较小的学习率意味着模型在训练时权重更新较为缓慢,通常可以使模型更稳定地收敛,但可能需要更多的训练迭代次数。 |
| 训练次数 | 训练次数指的是模型在整个训练数据集上进行迭代训练的次数。每次迭代都会更新模型的权重,训练次数越多,模型越有可能充分学习数据中的模式,但也可能导致过拟合。 |
| 输入序列分词后的最大长度 | 这个参数规定了输入序列在进行分词处理后允许的最大长度。如果输入序列超过这个长度,可能需要进行截断或其他处理。 |
| 数值精度 | 数值精度通常涉及到模型计算中所使用的数据类型(如 float32、float16 等)。"auto" 可能表示系统会自动选择合适的数值精度。 |
| lora 作用模块 | 选择模型的全部或特定模块层进行微调优化。 |
| LoRA 秩 | 决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| Lora 随机丢弃 | 这个参数通常用于防止过拟合。Lora 随机丢弃以一定概率随机丢弃神经元的输出,这里 0.01 表示 1% 的概率。 |
| LoRA 缩放系数 | 定义了LoRA适应的学习率缩放因子。该参数过高,可能会导致模型的微调过度,失去原始模型的能力;改参数过低,可能达不到预期的微调效果。 |
# 3.模型部署&评估
# 3.1 发布服务
首先在开放平台-控制台 (opens new window)中创建应用(若已创建,则无需重复),在模型管理中选择相应任务点击【发布为服务】,将其授权至所创建的应用完成发布。发布成功后可以点击【体验】,获得在线体验,也可以点击【新增版本】继续精调模型获得性能更佳的模型,注意:精调后的需要再次【更新服务】选择最新版本才可体验最新效果。
1.点击创建应用 |
2.填写相关信息 |
|---|


3.发布为服务 |
4.体验或继续优化 |
|---|


# 3.2 在线体验
在「体验中心」页面的「我的服务」将同步该模型能力,可以看到已经精调出一个商品情感分类模型。
1.点击体验 |
2.选择服务输入指令 |
|---|


# 3.3 批量推理
您可以在「批量推理」板块,创建或发起模型批量推理,选择推理数据集,可支持多个模型同时推理。
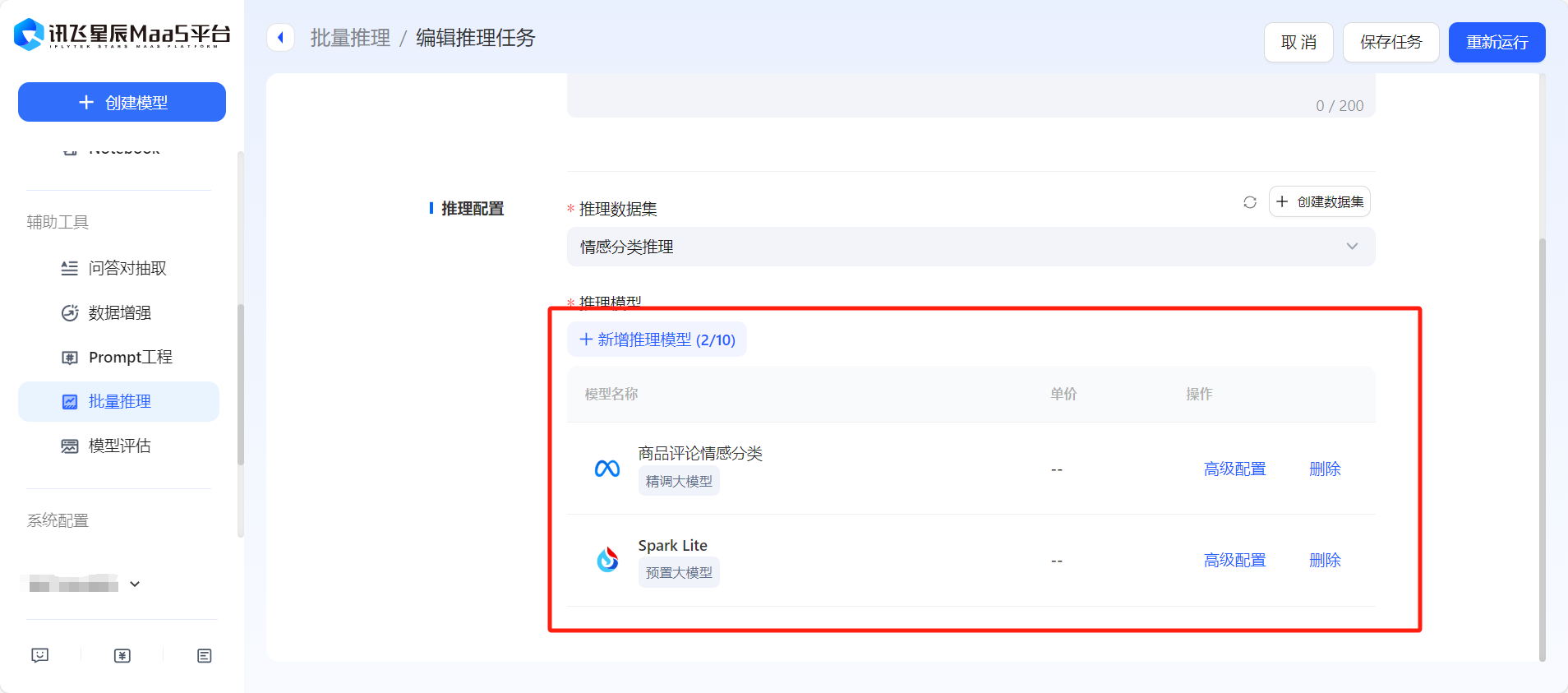 创建批推理任务
创建批推理任务
在任务状态变为已完成后,可以选择查看评估报告或导出评估结果已得到精调前后效果对比,可以看到精调后的模型回答更加准确~
批推理任务状态 |
批推理结果 |
|---|


# 3.4 模型评估
在【模型评估】板块,可以基于批量推理结果对模型的输出效果进行全方位评价,提供相似度打分和裁判员打分两种方式,可以根据任务类型进行选择。
1. 创建模型评估 |
2. 模型评估结果 |
|---|


# 4. 进阶训练
前文我们已经完整地进行了一次大模型微调的实战操作。请结合以下业务背景,自主完成一次模型微调的实践。
**法律咨询大模型**
随着民众法治意识增强,法律咨询需求激增。法律咨询机构与线上平台不断涌现,却面临人工解答效率低、通用大模型专业性不足的难题。这些法律咨询服务提供方,为了能够高效应对大量来自不同领域、涉及各类法律问题的咨询,急需借助先进的人工智能技术来辅助进行法律咨询回复工作。
然而,市面上通用的大模型往往缺乏足够专业且贴合实际法律咨询场景的能力,对于复杂的法律问题,回复的准确性和专业性难以保证,无法满足法律咨询业务严谨性的要求。
参考数据集格式:
{"prompt": "假设你是一位法律专家,熟知所有法律知识,能够以专业的角度解答所有的法律咨询", "input": "我自己的公司我是法人没有股东挪用公司的钱会触犯法律吗", "output": "成立公司以后,个人的钱与公司的钱是独立的。即使公司只有一个股东,如果此股东将钱占有已有,则为职务侵占罪,如果是挪用后从事经营活动,超过3个月以上的,属于挪用资金罪。简单举例,公司经营困难,负债累累,但是不会要求股东个人偿债。同样,公司盈利后,股东可分红,不能任意挪用。否则会造成公司人格混同。"}
✨✨更多精彩内容,尽在星辰MaaS精调平台 (opens new window)!欢迎体验~