# 1.人工智能与机器学习
人工智能是一个很庞大的研究领域,虽然人们对于人工智能相关的理论研究和算法开发达到了一定高度,迄今为止我们掌握的能力仍然非常有限。人工智能的范畴包括机器学习,机器学习是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心组成部分,它是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。深度学习是机器学习中的一个研究方向,深度学习通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。
# 2.机器学习中的深度学习
深度学习(deep learning)是机器学习的分支,是一种以人工神经网络为架构,对资料进行特征学习的算法。这里解释一下特征学习,特征学习是学习一个特征的技术的集合:将原始数据转换成为能够被机器学习来有效开发的一种形式。它避免了手动提取特征的麻烦,允许计算机学习使用特征的同时,也学习如何提取特征。简而言之,就是学习如何学习。 深度学习的好处是低成本高效率的获取信息特征。至今已有数种深度学习框架,如深度神经网络、卷积神经网络和深度置信网络和循环神经网络已被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
# 3.走近人工智能
每年的英语四六级考试成绩总能牵动一些小伙伴的心情,如果请你判断小飞同学的成绩是否合格,那么应该难不倒你,因为我们很清楚其中的判断逻辑,分数大于等于425分就合格,424分就“杯具”了。若是让你来完成这一段代码,你会怎么做呢?



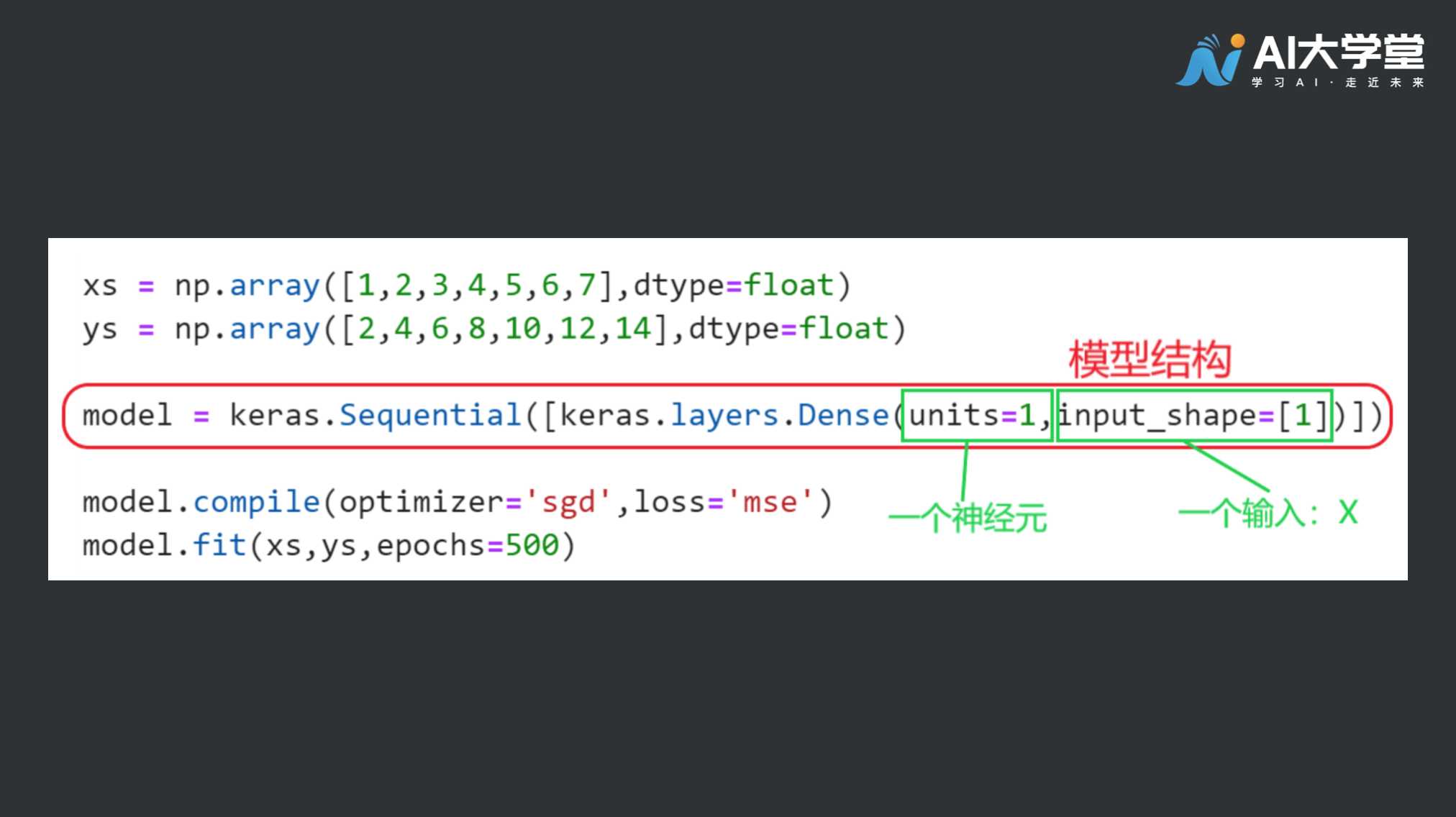
X = 1,2,3,4,5, 6, 7
Y = 2,4,6,8,10,12,14
2
这些数字当中的各个X值,它们和Y值之间存在着一种关系,你能找出其中的规律吗? 很简单,Y = 2X 你是怎么得出这个规律的呢? 你可能注意到当X = 1时,Y 是 X 的 2 倍,再看看第二组,X = 2时,Y = 4,现在很可能就是 Y = 2X 的关系,我们想验证一下猜想,于是又看了X = 3,4,5,6,7时 Y 的对应值是否和我们的猜测吻合,发现是的,于是我们得出 Y = 2X 的规律。这样的思考过程正是所有机器学习运算的方式。下面,我们用机器学习的思路去实现这一过程。
# 4.代码讲解

# 4.1数据部分
首先是数据,数据包括输入数据(X)以及对应的标签(Y),这里数据和标签是一起交给计算机进行学习的。

# 4.2模型部分
再来是网络模型构造,我们需要根据任务挑选不同的模型进行学习,例如线性模型Y=kX + b ,或者复杂的神经网络模型。
# 4.3损失函数和优化器
训练时,模型会以损失函数来衡量猜测结果的准度


# 4.4训练模型

# 4.5评价模型


# 5.小结
传统的编码模式,是程序员写好规则,有输入就有预定的输出。机器学习呢,是程序员写好框架,让机器学习到一个比较好的规则,能够对数据输出靠谱的结果。可能在这个例子中,感觉机器学习也不过如此,其实在很多复杂的问题上机器学习往往能发挥出极大的使用价值。

# 完整代码:
import tensorflow as tf
import numpy as np
from tensorflow import keras
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0], dtype=float)
ys = np.array([2.0, 4.0, 6.0, 8.0, 10.0, 12.0, 14], dtype=float)
model.fit(xs, ys, epochs=500)
print(model.predict([8.0]))
2
3
4
5
6
7
8
9
# 6.课堂练习
1、还记得人工智能的层次结构吗,左右两边哪个图标识的是正确的?不记得了就再看看本文吧。
