
之前的课程我们熟悉了用TensorFlow对简单数据进行线性预测,现在我们尝试利用新模型对图片完成分类预测。我们开始吧。请问下图片中你看到了几只鞋?


# 1.Fashion-MNIST 数据集
Fashion-MNIST是由德国电商平台(Zalando)发布的数据集。数据集中包含了10个类别的图像,分别是:T恤、牛仔裤、套衫、裙子、外套、凉鞋、衬衫、运动鞋、包、短靴。

28*28的灰度图,非常的小。图片小也有好处,需要计算的参数相应减少,计算机处理速度也更快。

# 1.1代码讲解:
# 1.1.1数据准备
导入必要的包:
import tensorflow as tf
from tensorflow import keras
2
Fashion MNIST 是内置于TensoFlow的,所以很容易用这样的代码来加载。
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
2
训练图组包含60000张图片,像是这样的灰度图片。

# 1.1.2构造模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
2
3
4
5
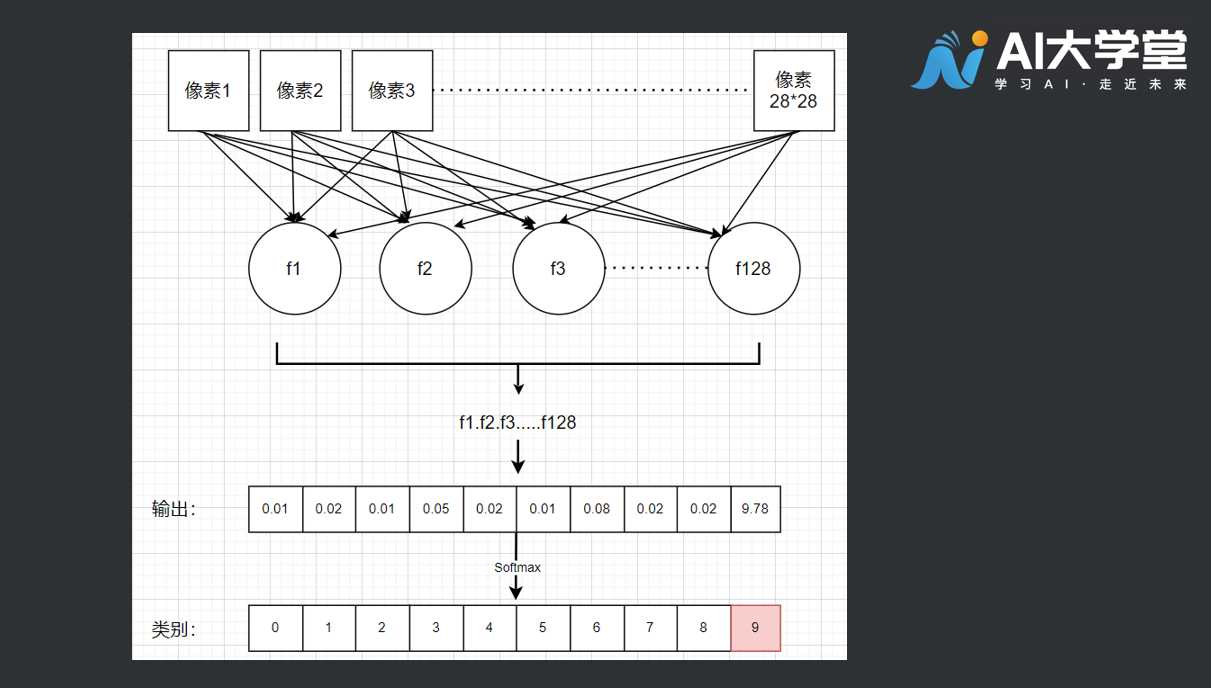
在第一层的网络中,我们的输入形状是28*28,这里的形状就是图片的长度和宽度。
keras.layers.Flatten(input_shape=(28, 28))
最后一层是10,是数据集中各种类别的代号,数据集总共有10类,这里就是10 。
keras.layers.Dense(10, activation=tf.nn.softmax),
所以神经网络有点像滤波器(过滤装置),输入一组28*28像素的图片后,输出10个类别的判断结果。那这个128的数字是做什么用的呢?
keras.layers.Dense(128, activation=tf.nn.relu),
我们可以这样想象,神经网络中有128个函数,每个函数都有自己的参数。

model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy')
2
神经网络会对这些参数随机地初始化一些数值,损失函数会衡量结果精准与否。然后通过优化函数,各个函数会产生新的参数,去检查是否还有进步空间。你可能对这些函数感到好奇,它们叫做激活函数。
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
2
3
第一个激活函数, activation=tf.nn.relu 在128层函数的这层,叫RelU,也叫线性整流函数,它的左右就是当函数值大于零时,把数值传递下去,函数值小于零时丢弃(赋值为零)。



# 1.1.3训练、评估模型
model.fit(train_images, train_labels, epochs=5)
这次我们只训练5遍,还记得之前我们还有1万张图片和对应的标签没有用于训练吗?这些是模型“还没见过”的图像。所以可以用来测试模型的效能,测试方法就是将图像传递给评估方法,就像这样:
test_loss, test_acc = model.evaluate(test_images, test_labels)
# 1.1.4模型预测
最后我们可以用 model.predict 来预测新图像:
predictions = model.predict(my_images)
这就是电脑查看和识别图像的一套方法,赶紧去试试吧!
# 1.2完整代码
import tensorflow as tf
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy')
model.fit(train_images, train_labels, epochs=5)
predictions = model.predict(test_images)
print(predictions[0]) #打印网络预测结果
print(test_labels[0]) #打印答案(标签label)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2.拓展阅读
# 2.1为什么要使用激活函数?
答:为了对网络模型提供非线性。
追问:为什么网络模型需要具备非线性分类的能力?
答:因为线性分类是用直线进行分类,而现实的问题往往是非线性的。
