我们在之前的课程中学习了线性模型的搭建和训练,它们的训练数据呈现出这样的特点:一组特征对应一个标签。例如一个卧室的房子卖10万,波士顿房子在13个因素的影响下给出了房屋报价。在实际的场景中,我们的数据集可能没有如此完整的对应关系,可能我们只有卧室的数量,而其他的信息不完整。针对数据不全或标注成本高昂的情景,这节课介绍一种新的方法,无监督学习。我们利用鸢尾花的数据集进行训练,人为制造无标签数据进行演示,一起来学习吧。
# 1.鸢尾花问题背景
鸢尾花数据集可不是无名之辈,它是由大名鼎鼎的费舍(Ronald Fisher)提出,1890年出生于英国伦敦,是著名的统计学家和遗传学家。也是他发明了最大似然估计和方差分析!鸢尾花数据集最初由Edgar Anderson 测量得到,而后费舍于1936年发表的文章《The use of multiple measurements in taxonomic problems》中被使用,用其作为线性判别分析(Linear Discriminant Analysis)的一个例子,证明分类的统计方法,从此而被众人所知,尤其是在机器学习这个领域。



# 2.代码示例(线性模型)
导入必要的库
import numpy as np
import tensorflow as tf
from sklearn import datasets
2
3
# 2.1数据准备
x_train = datasets.load_iris().data
x_label = datasets.load_iris().target
2
# 2.2设置模型
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
2
3
设置损失函数和优化器
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
)
2
3
# 2.3训练模型
model.fit(x_train, x_label, epochs=300, validation_split=0.2, validation_freq=20)
至此,模型已训练完成,我们来测试下效果。这是计算机没有见过的一条数据:[5.1, 3.5, 1.4, 0.2] ,根据该数据的花瓣和花萼的长宽,它的类别属于山鸢尾,类别号为0 。
# 2.4测试评估
mydata = np.array([[5.1,3.6,1.31,0.4]])
print(model.predict(mydata))
2
# 2.5完整代码示例(线性模型)
import numpy as np
import tensorflow as tf
from sklearn import datasets
x_train = datasets.load_iris().data
x_label = datasets.load_iris().target
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy()
)
model.fit(x_train, x_label, epochs=300, validation_split=0.2, validation_freq=20)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
预测时会打印3个分类的概率,每个概率分别对应分类编号0、1、2,得分最高的那一类即为模型预测的分类。
# 3.无监督学习
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。 现在如果我们只有三类花朵的各种尺寸,缺乏标签数据,可以利用某种手段达到分类目的吗?答案是肯定的,我们用到了无监督学习的技巧,无监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情。
# 4.代码示例(无监督)
引入必要的机器学习库文件
from sklearn import datasets
import pandas as pd
from sklearn.mixture import GaussianMixture
from sklearn.metrics import calinski_harabasz_score
2
3
4
数据准备,这里的数据是源自sklearn库,可直接加载,加载方法如下:
ds = datasets.load_iris()
df_ds = pd.DataFrame(ds.data, columns=ds.feature_names)
2
使用的分类模型为高斯混合模型,使用最大期望算法 (Expectation Maximization Algorithm)进行迭代:
gmm = GaussianMixture(n_components=3)
其中的n_components参数可以简单理解为将样本分为3个类别。 这里简要介绍下最大期望算法(简称:EM),它用于表明给定具有缺失数据的参数估计问题,EM算法可以通过生成对丢失数据的可能猜测来迭代地解决该问题,然后通过使用这些猜测来最大化观察的可能性。 迭代训练模型:
gmm.fit(df_ds)
在训练过程中,模型的停止迭代阈值默认值为0.001,可以理解为当模型训练到满足默认要求的时候自动退出计算,默认计算次数为100次,如果计算了100次仍然没有触发自动终止的条件,那么模型也会退出计算,返回最后一次的计算结果。 预测模型:
label=gmm.predict(df_ds)
这里我们用的预测数据与训练数据相同,之所以可以这么用,是因为在训练的过程中我们没有为数据打标签,就是说我们没有告诉计算机每条数据对应的是什么种类的花。
# 完整代码实现(无监督)
from sklearn import datasets
import pandas as pd
from sklearn.mixture import GaussianMixture
from sklearn.metrics import calinski_harabasz_score
ds = datasets.load_iris()
df_ds = pd.DataFrame(ds.data, columns=ds.feature_names)
gmm = GaussianMixture(n_components=3)
gmm.fit(df_ds)
label=gmm.predict(df_ds)
print("准确率:{:.2%}".format(len(label[label==ds.target])/len(label)))
print("得分:{:}".format(calinski_harabasz_score(df_ds, label)))
2
3
4
5
6
7
8
9
10
11
12
13
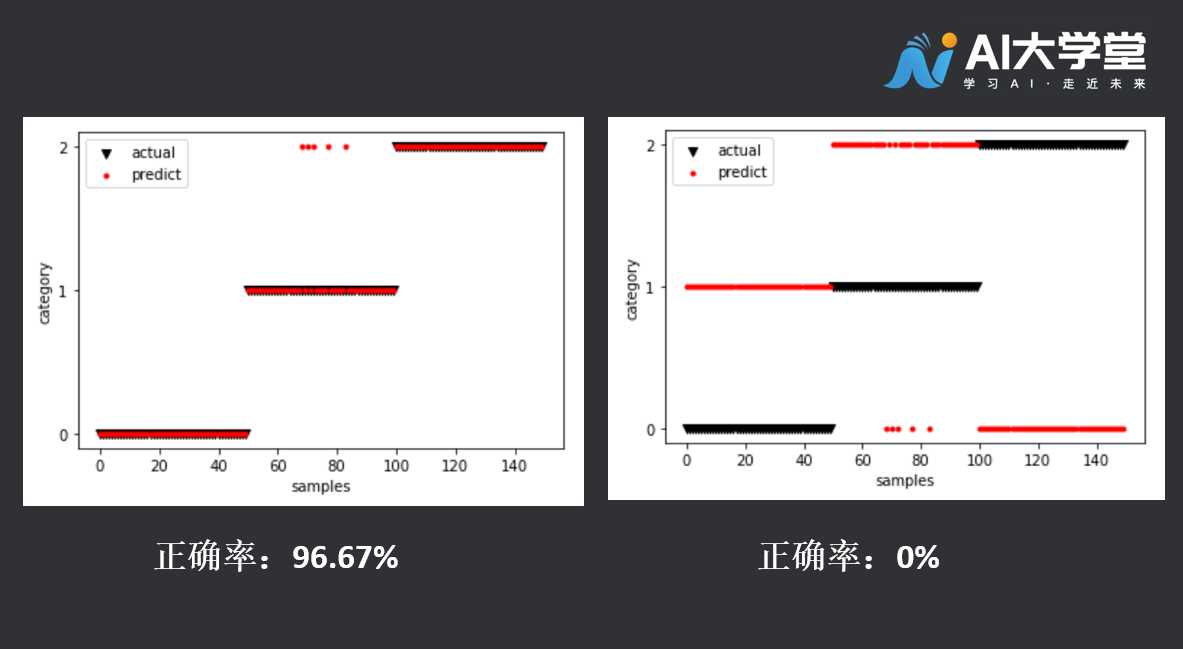
绘图查看:
import matplotlib.pyplot as plt
plt.scatter([i for i in range(len(ds.target))], ds.target, color='black', marker='v')
plt.scatter([i for i in range(len(label))], label, color='red', marker='.')
plt.yticks([0, 1, 2])
plt.xlabel('samples')
plt.ylabel('category')
plt.legend(['actual', 'predict'])
plt.savefig('predict.jpg', dpi=800)
2
3
4
5
6
7
8
你得到了什么样的预测图呢?是33%、67%、96%,亦或是0%的正确率?都有可能。
# 5.拓展阅读
无监督学习有很多应用场景,比如它可以发现异常行为,比如人们可以对金融市场的操作行为进行分类,虽然开始的时候我们并不知道计算机分出的类别代表什么含义,但人们拿到一类的数据稍加分析就能得出结论,一些违规的操作会被区分出来,甄别起来就容易了很多。

